1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
|
import numpy
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.safari.options import Options
import time
import requests
from PIL import Image
import io
import cv2
class SliderCaptchaDemo(object):
URL = "https://accounts.douban.com/passport/login"
BK_IMAGE = 'bk_image.png'
FULL_SLIDER_IMAGE = "full_slider_image.png"
SLIDER_IMAGE = "slider_image.png"
TIME_OUT = 20
def __init__(self):
option = ChromeOptions()
# 解决滑块无法滑动的问题
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('detach', True)
# 创建一个对象,控制chrome浏览器
self.driver = webdriver.Chrome(options=option)
# 创建 SafariOptions 实例
# option = Options()
# # 添加选项
# option.add_argument('-enableFullPageScreenshot')
# option.add_argument('-allow-file-access-from-files')
# self.driver = webdriver.Safari(options=option)
self.driver.set_window_size(1000, 600)
self.panel_element = None
# self.driver.maximize_window()
def loadLoginPage(self):
self.driver.get(SliderCaptchaDemo.URL)
script = 'Object.defineProperty(navigator, "webdriver", {get: () => false,});'
self.driver.execute_script(script)
wait = WebDriverWait(self.driver, SliderCaptchaDemo.TIME_OUT)
login_element = wait.until(
EC.visibility_of_element_located((By.XPATH, "//div[@class='account-tabcon-start']"))
)
# 使用 XPath 定位手机号码输入框
phone_input = login_element.find_element(By.XPATH, "//input[@placeholder='手机号']")
phone_input.send_keys("15210795183")
# 使用 XPath 定位密码输入框
code_input = login_element.find_element(By.XPATH,
"//div[@class='account-form-field account-form-codes']/input[@id='code']")
# 显式等待,直到获取验证码按钮可点击;
# 有时候,如果页面中的元素尺寸或位置发生变化时,使用Selenium自动点击元素可能会失败。
# 解决这种问题的一种方法是使用JavaScript的click()方法来触发元素的点击操作。
get_code_button = WebDriverWait(self.driver, 10).until(
EC.element_to_be_clickable((By.CLASS_NAME, "get-code"))
)
self.driver.execute_script("arguments[0].click();", get_code_button)
time.sleep(5)
self.loop()
def get_images(self):
if self.panel_element is None:
# 在网页中,有时会使用 iframe 或 frame 元素嵌入其他网页或内容。如果要在 Selenium 中操作这些嵌入的网页或内容,就需要先切换到相应的 iframe 或 frame 中。
# 使用 driver.switch_to.frame() 方法可以通过 iframe 或 frame 元素的索引、名称或 WebElement 对象来切换到相应的 iframe 或 frame 中
# 使用 driver.switch_to.default_content() 方法可以切换回默认的上下文,即切回到主文档或最外层的窗口,以便继续操作其他元素。
iframe = self.driver.find_element(By.ID, "tcaptcha_iframe_dy")
self.driver.switch_to.frame(iframe)
panel_element = WebDriverWait(self.driver, 12).until(
EC.visibility_of_element_located((By.CLASS_NAME, "body-wrap"))
)
self.panel_element = panel_element
print(f"元素已经加载完成:", self.panel_element)
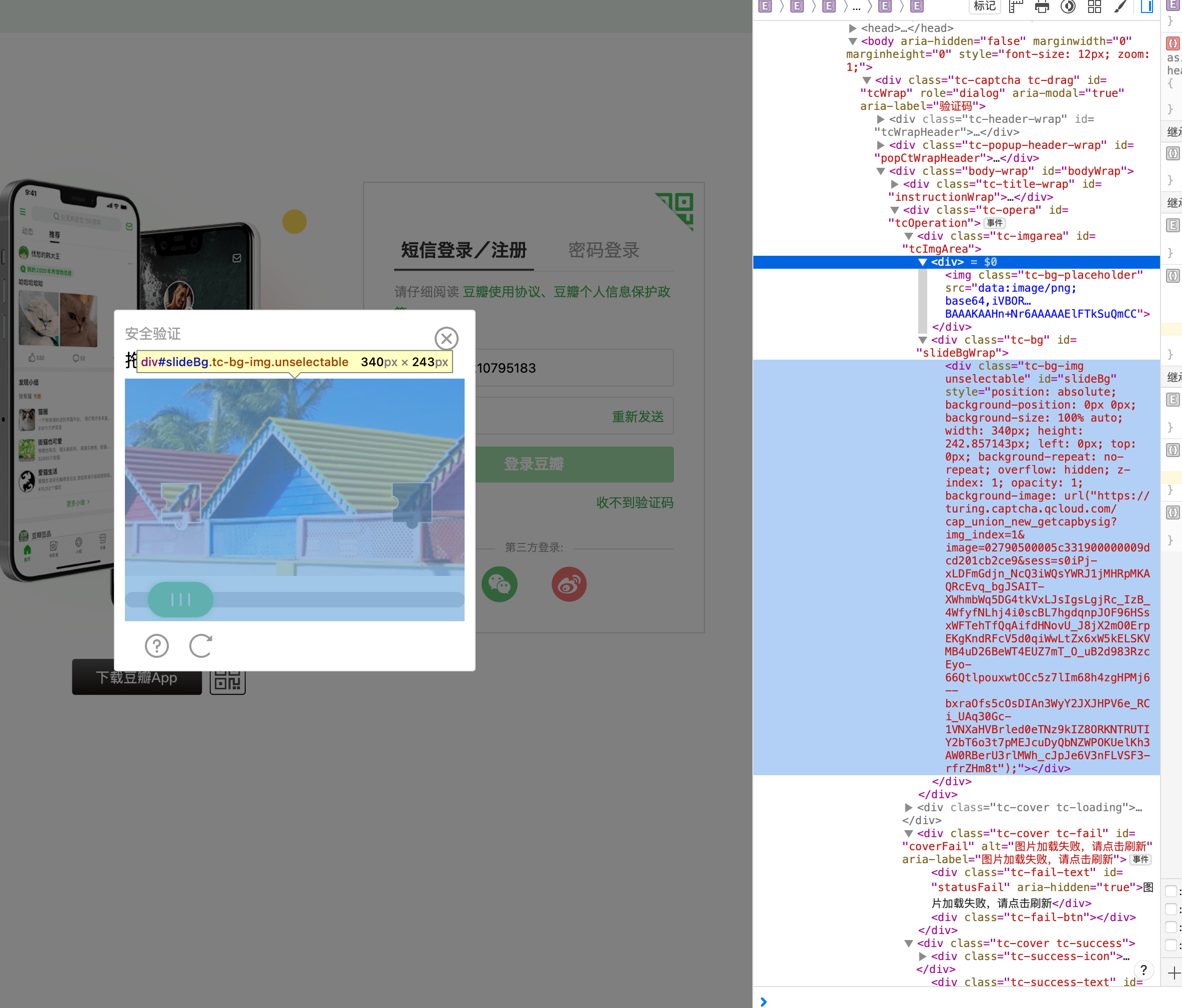
element = self.panel_element.find_element(By.XPATH, "//*[@id='slideBg']")
# 获取元素的background-image属性值
bg_image = element.get_attribute("style")
# 从background-image属性值中提取图片链接
start_index = bg_image.index("(") + 1
end_index = bg_image.index(")")
image_url = bg_image[start_index:end_index]
image_url = image_url.replace('"', '')
print(f"背景图片链接:{image_url}")
response = requests.get(image_url, stream=True)
bk_image = Image.open(io.BytesIO(response.content))
bk_image.save(SliderCaptchaDemo.BK_IMAGE)
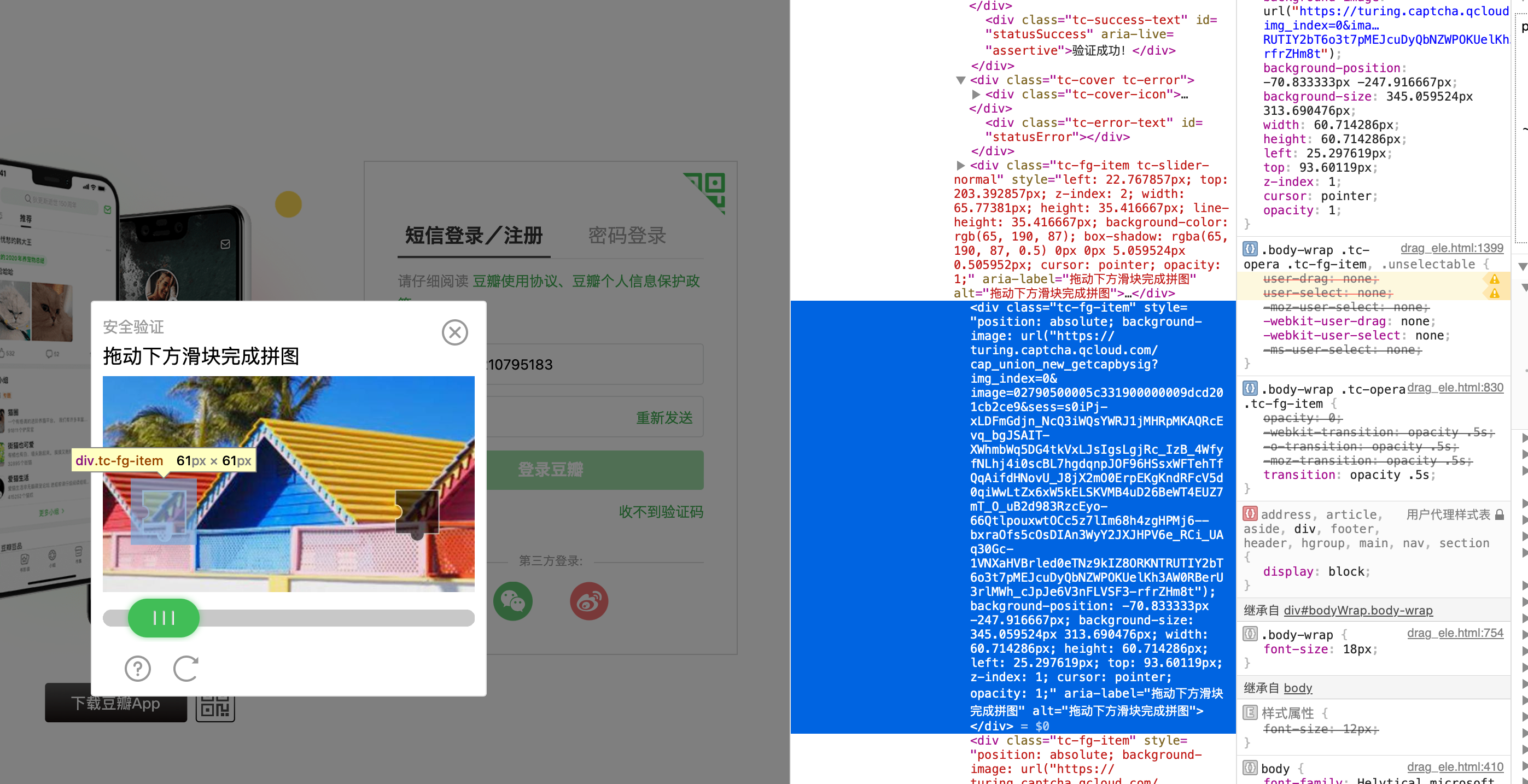
# 找到指定的元素
slider_element = self.panel_element.find_element(By.XPATH, "//*[@id='tcOperation']/div[@class='tc-fg-item']")
# 获取元素的background-image属性值
slider_image = slider_element.get_attribute("style")
# 从background-image属性值中提取图片链接
start_index = slider_image.index("(") + 1
end_index = slider_image.index(")")
image_url = slider_image[start_index:end_index]
image_url = image_url.replace('"', '')
print(f"图片链接:{image_url}")
response = requests.get(image_url, stream=True)
image = Image.open(io.BytesIO(response.content))
image.save(SliderCaptchaDemo.FULL_SLIDER_IMAGE)
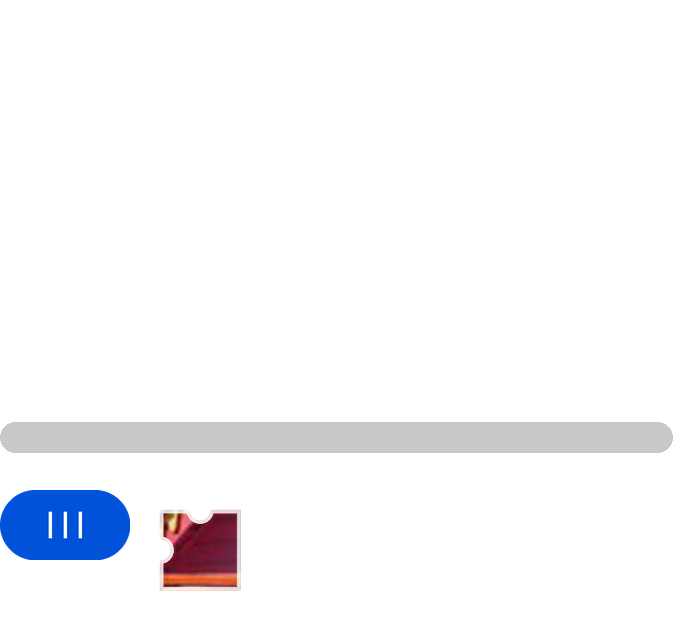
# 获取验证码x,y轴坐标
crop_point = (71, 248)
# 获取验证码的长宽
crop_size = (61, 61)
# 设备分辨率为2
scale = 2
rangle = (crop_point[0] * scale,
crop_point[1] * scale,
crop_point[0] * scale + crop_size[0] * scale,
crop_point[1] * scale + crop_size[1] * scale
)
verification_image = image.crop(rangle)
# verification_image = verification_image.convert('RGB')
# 保存我们截取的验证码图片,并读取验证码内容
verification_image.save(SliderCaptchaDemo.SLIDER_IMAGE)
# 返回路径
return SliderCaptchaDemo.BK_IMAGE, SliderCaptchaDemo.SLIDER_IMAGE
def loop(self):
# 得到验证码图片
full_image, slider_image = self.get_images()
# 匹配缺口照片在完整照片的位置,因设备分辨率为2,所以图片匹配的像素距离除2;因滑块相比图片最左边缘已偏移23,所以减去23
slider_offset = self.match_picture(full_image, slider_image) / 2 - 23
print(f"match_picture 滑块移动:{slider_offset}")
find_image_slider_offset = self.find_image(full_image, slider_image) / 2 - 23
print(f"find_image 滑块移动:{find_image_slider_offset}")
# 机器模拟人工滑动轨迹
self.sliding_track(slider_offset)
# 若失败,循环触发。
if self.judge_show():
self.loop()
else:
self.driver.switch_to.default_content()
@staticmethod
def find_image(full_image, slider_image):
# 读取图片文件信息
img_full = cv2.imread(full_image)
# 以灰度模式加载图片
template = cv2.imread(slider_image)
# 方法
methods = [cv2.TM_SQDIFF_NORMED, cv2.TM_CCORR_NORMED, cv2.TM_CCOEFF_NORMED]
# 记录每个方法的距离
left = []
# 最接近值
min_ = []
for method in methods:
# 匹配
res = cv2.matchTemplate(img_full, template, method)
# 获取相关内容
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
if method == cv2.TM_SQDIFF_NORMED:
min_.append(min_val - 0.0)
left.append(min_loc[0])
else:
min_.append(1.0 - max_val)
left.append(max_loc[0])
index = min_.index(numpy.min(min_))
return left[index]
@staticmethod
def match_picture(full_image_path, slider_image_path):
# 读取背景图片和缺口图片
full_image = cv2.imread(full_image_path)
slider_image = cv2.imread(slider_image_path)
# 识别图片边缘,获取灰度图
full_image_edge = cv2.Canny(full_image, 100, 200)
slider_image_edge = cv2.Canny(slider_image, 100, 200)
cv2.imwrite("full_image_edge.png", full_image_edge)
cv2.imwrite("slider_image_edge.png", slider_image_edge)
# 转换图片格式,灰度图像转换为 RGB 彩色图像,以便于与其他彩色图像进行叠加或处理
# !!!很关键!否则缺口匹配将不准确
full_image_grey = cv2.cvtColor(full_image_edge, cv2.COLOR_GRAY2RGB)
slider_image_grey = cv2.cvtColor(slider_image_edge, cv2.COLOR_GRAY2RGB)
cv2.imwrite("full_image_grey.png", full_image_grey)
cv2.imwrite("slider_image_grey.png", slider_image_grey)
# 缺口匹配
res = cv2.matchTemplate(full_image_grey, slider_image_grey, cv2.TM_CCOEFF_NORMED)
# 寻找最优匹配
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
return max_loc[0]
# 判断是否完成操作
def judge_show(self):
time.sleep(2)
show = 'return document.getElementsByClassName(\'tc-captcha tc-drag\')'
show_is = self.driver.execute_script(show)
return len(show_is) > 0
def sliding_track(self, distance):
# 获取轨迹
track = self.get_tracks(distance)
# 获取按钮
slider = self.panel_element.find_element(By.XPATH,
"//*[@id='tcOperation']/div[@class='tc-fg-item tc-slider-normal']")
action_chains = ActionChains(self.driver)
action_chains.click_and_hold(slider).perform()
print(track)
for t in track:
action_chains.move_by_offset(xoffset=t, yoffset=0).perform()
action_chains.release().perform()
time.sleep(2)
@staticmethod
def get_tracks(distance, rate=0.4, t=0.2, v=0):
tracks = []
# 加速减速的临界值
mid = rate * distance
# 当前位移
s = 0
# 循环
while s < distance:
# 初始速度
v0 = v
if s < mid:
a = 20
else:
a = -3
# 计算当前t时间段走的距离
s0 = v0 * t + 0.5 * a * t * t
# 计算当前速度
v = v0 + a * t
# 四舍五入距离,因为像素没有小数
tracks.append(round(s0))
# 计算当前距离
s += s0
return tracks
|